


AI data cleaning is emerging as a critical response to slow, manual data preparation that undermines analytics and AI. By learning patterns, detecting anomalies, and improving continuously, AI-driven cleaning scales where rule-based methods fail. Embedded within modern data stacks, platforms like OvalEdge combine automation with governance to deliver faster, trusted data for analytics and ML.
Data teams often struggle with getting usable data fast enough to produce it. Dashboards stall, models wait, and decisions slow down because someone is still fixing duplicates, formats, or missing values behind the scenes.
This is why AI data cleaning is gaining momentum. As data volumes grow and analytics move closer to real-time, manual and rule-based cleansing can’t keep up. At the same time, organizations can’t afford data fixes that bypass data governance. Cleaning efforts now need to preserve lineage, ownership, and auditability, especially as analytics and AI outputs increasingly inform regulated business decisions.
Despite years of investment in modern data tools, the problem persists.
A 2025 Alteryx survey found that 76% of data professionals still rely on spreadsheets as their primary cleaning tool.
In this guide, we’ll break down what AI data cleaning actually is, how it works in practice, how it compares to traditional data cleansing, where it fits in modern data stacks, and what capabilities matter most when evaluating AI data cleaning software for analytics and ML workflows.
What is AI data cleaning?
AI data cleaning is the use of machine learning to automatically detect, correct, and standardize data errors at scale. AI models identify duplicates, missing values, anomalies, and inconsistencies across datasets. Algorithms learn patterns from historical corrections to improve data quality over time.
AI data cleaning reduces manual data preparation and supports analytics, machine learning, and governance workflows. This approach operates continuously within data pipelines and improves accuracy, consistency, and trust in enterprise data.
Once you move past the definition, the difference between AI data cleaning and basic automation becomes easier to see. Traditional approaches depend on fixed rules, and AI systems learn from data behavior and adjust as patterns change.
In practice, AI data cleaning focuses on a few core outcomes:
-
Learning-based detection, not static rules: Models learn what “normal” data looks like, and flag exceptions when values drift, formats change, or relationships break.
-
Continuous improvement over time: Corrections made today help models make better decisions tomorrow, reducing repeat issues across datasets.
-
Scalability across growing data volumes: AI handles large, fast-changing datasets that manual or rule-based data cleansing struggles to maintain.
This makes AI data cleaning especially valuable for analytics, machine learning, and self-service use cases, where delays and rework quickly erode trust.
It’s also important to set expectations correctly. AI data cleaning does not replace data quality management or governance; it strengthens them. By embedding learning-driven detection and correction into data preparation workflows, teams improve reliability while keeping human oversight, policies, and accountability firmly in place.
|
Did you know? A 2025 IBM study found that 43% of COOs now rank data quality issues as their top data priority, reflecting growing operational pressure to trust analytics and AI-driven decisions. |
How AI data cleaning works in practice
AI data cleaning often sounds abstract until you see how it shows up in everyday workflows. In practice, it follows a set of repeatable steps that fit directly into existing data pipelines, working quietly in the background as data flows in, changes, and gets reused across teams.
In enterprise settings, AI data cleaning rarely operates as an unsupervised correction engine. AI typically flags issues and recommends corrections, while data governance policies and remediation workflows govern enforcement.
Human review loops remain in place for approvals, exceptions, and sensitive datasets, ensuring accuracy, accountability, and trust when AI gets something wrong.
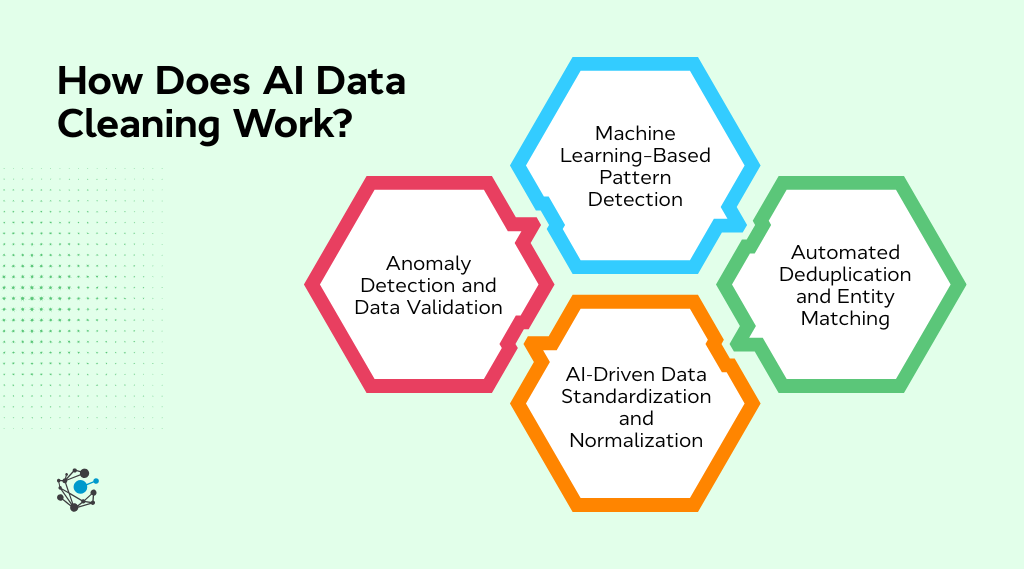
1. Machine learning–based pattern detection
AI models start by learning what “normal” data looks like from historical datasets. They pick up expected ranges, common formats, and relationships between fields, building a baseline that reflects how the data behaves over time. When new data arrives, the models compare it against these learned patterns to spot values that feel off.
This approach works across both structured and semi-structured data. Whether it’s an unusual spike in transaction amounts or inconsistent country codes appearing in different systems, AI adapts without requiring teams to constantly rewrite rules as data evolves.
2. Automated deduplication and entity matching
Deduplication is one of the most persistent challenges in data cleansing, especially when records live across multiple systems. AI tackles this by using probabilistic matching and fuzzy logic to determine whether two records actually represent the same entity, even when the details don’t line up perfectly.
Customer data is a familiar example. Names, emails, and addresses often vary between CRM, billing, and support platforms. Instead of relying on exact matches, AI scores similarity across multiple attributes, improving accuracy while reducing false matches that can distort analytics.
3. AI-driven data standardization and normalization
Inconsistent formats quietly undermine analytics more often than teams realize. Dates, currencies, units, and naming conventions frequently differ across sources, creating subtle issues that surface much later in reporting or modeling.
AI-driven standardization learns preferred formats and applies them consistently as data moves through pipelines. This reduces reconciliation work downstream and helps ensure that reports, dashboards, and models operate on aligned, comparable data.
4. Anomaly detection and data validation
Rather than treating validation as a one-time cleanup step, AI continuously monitors data for outliers, missing values, and suspicious patterns as they emerge. This makes data quality a living process instead of a reactive one.
By catching issues during ingestion or transformation, teams avoid downstream surprises that break dashboards or invalidate models. The result is cleaner data entering analytics and ML workflows, with fewer last-minute fixes and greater confidence in the outputs.
This shift is already paying off in practice.
A Forrester Consulting TEI study found that 61% of organizations saw measurable improvements in data quality and error reduction after introducing intelligent automation into their workflows.
As these workflows scale, the limitations of manual rules and scripted checks become harder to ignore. The contrast between learning-based automation and traditional data cleansing approaches becomes clear when you look at how each handles change, volume, and complexity.
|
If you’re curious about what it actually takes to operationalize data quality at scale, this deeper look at how enterprises approach governance, validation, and automation across the data lifecycle offers practical guidance on building trust from source to insight: |
AI data cleaning vs traditional data cleansing: Key differences
On the surface, AI data cleaning and traditional data cleansing aim for the same outcome: usable, reliable data. The difference shows up once data volume grows, sources multiply, and teams need results faster than manual processes can deliver.
|
Criteria |
Traditional data cleansing |
AI data cleaning |
|
Approach |
Relies on predefined rules and manual logic |
Uses machine learning to learn patterns and adapt over time |
|
Setup effort |
High initial setup and ongoing rule maintenance |
Lower manual setup after initial training |
|
Scalability |
Struggles as data volume and variety increase |
Scales across large, complex, and changing datasets |
|
Handling inconsistencies |
Requires explicit rules for each scenario |
Automatically detects patterns and anomalies |
|
Deduplication accuracy |
Deterministic and often rigid |
Probabilistic, context-aware entity matching |
|
Adaptability to change |
Breaks when schemas or formats change |
Continuously improves as data evolves |
|
Manual intervention |
Frequent human involvement is needed |
Minimal intervention, focused on exceptions |
|
Analytics readiness |
Slower time to trusted, usable data |
Faster data preparation for analytics and ML |
|
Maintenance overhead |
High, due to rule updates and rework |
Lower, as models self-adjust over time |
|
Best suited for |
Small, stable, well-defined datasets |
Enterprise-scale, dynamic, analytics-driven environments |
In practice, these differences become obvious very quickly. Rule-based approaches can work when data is predictable and changes infrequently, but they struggle as new sources, formats, and use cases enter the picture. Every change adds another rule, another exception, and another round of maintenance.
AI data cleaning shifts that burden by allowing systems to learn from data behavior instead of relying on constant human updates. This aligns better with modern data platforms, where quality needs to hold up across pipelines, analytics, and machine learning workloads without slowing teams down.
|
Expert Insight: The risk of getting this wrong is no longer theoretical. Gartner's 2024 press release predicts that at least 30% of generative AI projects will be abandoned by the end of 2025, with poor data quality cited as a key contributing factor. |
As data cleaning becomes more adaptive, the question shifts from whether automation helps to where it belongs. That makes the surrounding data architecture just as important as the cleaning logic itself.
How AI data cleaning fits into modern data stacks
AI data cleaning delivers the most value when it becomes part of the data stack itself rather than a separate cleanup step bolted on at the beginning or end. As data architectures evolve, cleaning increasingly happens in context, alongside storage, transformation, and consumption, where quality issues actually surface.

Integration with data warehouses, lakes, and lakehouses
In modern architectures, AI data cleaning operates close to storage and compute layers instead of sitting in an isolated preprocessing phase. Cleaning logic runs alongside ingestion and transformation, adapting as data flows into warehouses, lakes, and lakehouses.
This shift changes how teams think about data quality in practice:
-
Cleaning happens in context, not before data enters the platform
-
Quality checks adapt as schemas, sources, and formats evolve
-
Data movement is reduced, preserving lineage and operational context
The result is a setup where analytics and governance can coexist without slowing access or creating disconnected quality processes.
Role in ELT, data pipelines, and analytics workflows
Within ELT pipelines, AI continuously validates and enriches data as it moves through transformations. Instead of waiting for downstream failures, quality issues surface early, while fixes still have minimal impact.
Across workflows, this shows up in tangible ways:
-
Fewer broken dashboards caused by late-stage data issues
-
Faster refresh cycles with less rework between pipeline stages
-
Cleaner inputs for analytics and machine learning workloads
By reducing handoffs and last-minute fixes, teams spend less time firefighting and more time delivering insights.
Reducing manual data preparation for analytics and ML
This is where most teams feel the impact most clearly. AI reduces repetitive fixes, exception handling, and constant dependency on data engineering teams for quality issues that keep resurfacing.
That shift changes daily work patterns:
-
Analysts spend more time exploring and interpreting data instead of scrubbing it
-
ML practitioners reduce repeated preprocessing and feature cleanup
-
Quality improvements carry forward instead of resetting with each pipeline run
|
Here’s a fact: A Forrester Consulting TEI study on Dataiku reported a 413% ROI with a payback period of under six months, driven largely by reduced data preparation effort and faster analytics workflows. This kind of return highlights just how much time and cost still sit inside manual data preparation today. |
Platforms like OvalEdge reflect this approach by embedding AI-driven cleaning within governed, cataloged environments. Automation scales alongside metadata, lineage, and access controls, ensuring trust and traceability remain intact as data usage grows.
As AI data cleaning moves deeper into the stack, the focus shifts from individual fixes to sustained data health. At that point, the strength of the underlying platform becomes just as important as the intelligence of the models doing the work.
|
Also read: AI Data Governance: Compliance, Risk & Trust 2026 |
Core capabilities to look for in AI data cleaning software
Once teams move past the “should we automate data cleaning?” question, the focus shifts to how well a solution supports real-world, enterprise-scale workflows. Not all AI data cleaning software delivers the same value, so the underlying capabilities matter far more than surface-level features.
-
Automated data profiling and quality scoring: Ongoing visibility into accuracy, completeness, and consistency helps teams understand data health in context and prioritize issues before they impact analytics.
-
Intelligent deduplication and entity resolution: Probabilistic, context-aware matching improves cross-system consistency for customer, supplier, and product data without relying on rigid identifiers.
-
AI-driven validation and anomaly detection: Continuous monitoring flags outliers, missing values, and suspicious patterns as data moves through pipelines, reducing downstream failures.
-
Scalability and performance at enterprise volumes: AI data cleaning must keep pace with ingestion and transformation workloads without slowing pipelines or requiring constant tuning.
-
Governance, explainability, and auditability: Teams need to understand why data was flagged or corrected and ensure automation aligns with policies, access controls, and compliance requirements.
-
End-to-end traceability: Clear lineage from source to consumption makes it possible to trace data changes, validate corrections, and maintain trust across analytics and ML workflows.
|
Platforms like OvalEdge align well with these requirements by embedding AI-driven data cleaning within a governed data ecosystem. By connecting automation with metadata, lineage, and access controls, OvalEdge helps teams scale data quality improvements without creating blind spots or sacrificing accountability. |
At this stage, the goal is sustainable data quality that holds up as analytics, ML, and self-service use cases grow. When AI cleaning, governance, and traceability work together, data teams spend less time fixing problems and more time enabling decisions.
Conclusion
At some point, every data team reaches a breaking point where fixing data starts to cost more than the insights it enables.
AI data cleaning works best when it runs continuously inside the data platform, learning from change, reducing repetitive work, and strengthening trust as data moves from source to insight. That’s where platforms like OvalEdge come in.
Instead of treating data cleaning as a standalone task, OvalEdge helps teams embed AI-driven data quality directly into governed, cataloged environments. The focus stays on understanding the data landscape, identifying where quality breaks down, and operationalizing automation with full visibility, lineage, and accountability, so analytics and ML can scale with confidence rather than caution.
If reducing manual data preparation and improving data trust at scale is a priority, schedule a call with OvalEdge to see how AI data cleaning can fit into your existing data ecosystem and move your team from constant fixes to sustained data health.
FAQs
1. Can AI data cleaning handle unstructured or semi-structured data?
AI data cleaning can process semi-structured and unstructured data by identifying patterns, entities, and inconsistencies using machine learning. However, accuracy depends on data context, training quality, and how well metadata and schemas are defined.
2. Is AI data cleaning suitable for regulated industries like finance or healthcare?
Yes, but only when paired with strong governance, audit trails, and explainability. Regulated industries require visibility into how data is modified, which makes AI data cleaning most effective within governed, metadata-driven data environments.
3. How long does it take to see results after implementing AI data cleaning?
Organizations typically see early improvements within weeks, especially for high-volume datasets. Measurable gains include reduced manual effort, faster analytics readiness, and fewer downstream data quality issues impacting reports and models.
4. Does AI data cleaning replace data engineers or data quality teams?
No. AI data cleaning reduces repetitive manual work but still relies on human oversight for policy definition, exception handling, and governance. It shifts teams toward higher-value activities rather than eliminating their role.
5. What types of data benefit most from AI data cleaning?
High-volume, frequently changing datasets such as customer, transactional, operational, and event data benefit most. These datasets are prone to inconsistencies and require continuous validation, making them ideal for AI-driven automation.
6. How does AI data cleaning support self-service analytics?
By improving data consistency and reliability upstream, AI data cleaning ensures business users access trusted datasets. This reduces dependency on data teams, minimizes rework, and enables faster, more confident self-service analysis.
Deep-dive whitepapers on modern data governance and agentic analytics

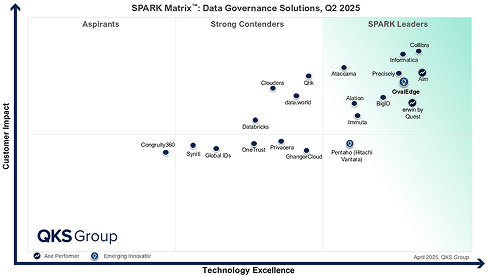
OvalEdge Recognized as a Leader in Data Governance Solutions
3ff1.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
aef2.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.