


Until recently, data lakes were the hot thing in data architecture, but more and more companies are turning away from this approach in search of an alternative.
This is because organizations using this centralized approach have found that it’s inefficient due to the over reliance on dedicated data teams. Not only did this cause bottlenecks, but it also caused problems, because it’s impossible for a data team to know and understand every team's needs.
In fact, Gartner reported that 80% of organizations seeking to scale digital business between now and 2025 will fail because they don’t take a modern approach to data and analytics governance.
For many in the industry, the alternative of choice is Data Mesh, a new architecture that could well be the solution.
There are already some fantastic resources available on the topic, but we wanted to give you a summary, and explain where OvalEdge fits in.
If you want to know more about implementing Data Mesh, or want to see how OvalEdge can help, schedule a demo here.
What is Data Mesh?
As with any new concept or technology, the first thing we need to know is what Data Mesh actually is? It’s only a couple years old, so resources are scarce. But as it was created by Zhamak Dehghani at ThoughtWorks, it makes sense to kick things off with their definition:
Data Mesh is an analytical data architecture and operating model where data is treated as a product and owned by teams that most intimately know and consume the data.
This is a good high-level definition, and it introduces the core concept that data ownership should be decentralized.
To help achieve this, there are four principles of Data Mesh:
- Domain Ownership
- Data as a product
- Self-serve data platforms
- Federated computational governance
These principles form an architecture that can be applied across your business, helping avoid bottlenecks and creating shared ownership.
But before we delve further into these principles, it’s important to first talk about what Data Mesh isn’t.
- It isn’t something that can be implemented by a single person
- No single tool can generate or implement a ‘mesh’
- It’s not a silver bullet that will magically fix all your data issues
Instead, it’s a strategic framework for getting value from data by changing how you share data, structure your teams, and carry out governance. Decentralization lies at the heart of it, and if implemented well, your data can go beyond BI reports to drive innovation and analytics at scale.
It’s called a “mesh” because teams can access data products created and owned by other teams, creating a connected network of insights across the organization.
When should you implement Data Mesh?
Data Mesh is not the right fit for every organization, and implementing it before you are ready can create more problems than it solves. Before committing to the architecture, it helps to honestly assess where your organization stands today.
Here are the signals that suggest Data Mesh is worth pursuing:
You have multiple domains generating data independently
If your marketing, finance, sales, and operations teams each own significant data pipelines and are constantly waiting on a central data team to deliver what they need, that bottleneck is exactly what Data Mesh is designed to fix. Organizations with three or more distinct business domains producing analytical data regularly tend to see the clearest benefit.
Your central data team has become a bottleneck
When business teams are queuing for weeks to get access to reports, dashboards, or data sets they need for decisions, the centralized model has reached its limit. Data Mesh moves ownership closer to the people who understand the data, which cuts that waiting time significantly.
You have executive support for organizational change
This one is non-negotiable. Data Mesh is not just a technology shift. It changes how teams are structured, how ownership is defined, and how governance decisions get made. Without buy-in from leadership, implementations stall once they hit cross-departmental boundaries. Thoughtworks, which has guided some of the largest Data Mesh rollouts globally, consistently lists executive sponsorship as the single biggest predictor of success.
Your teams have domain expertise, not just technical skills
Data Mesh depends on domain teams owning their data products end to end. That requires people who understand both the business context and the technical requirements. If your teams currently rely entirely on a central data engineering group to interpret and move their data, there will be a skills gap to close before implementation makes sense.
You are prepared for a long-term commitment
Data Mesh is not a project you complete and move on from. It is an ongoing operating model. Organizations that approach it as a short-term migration tend to struggle. The ones that succeed treat it as a multi-year transformation with clear milestones along the way.
Signs Data Mesh may not be the right move yet
If your organization has fewer than two or three data-heavy domains, a well-managed data warehouse or data lakehouse will likely serve you better with far less organizational disruption. Data Mesh introduces real coordination overhead, and that overhead only pays off at a certain scale of complexity.
Similarly, if your data governance practices are still maturing, building a federated governance model on top of a shaky foundation tends to amplify the existing gaps rather than solve them. Getting your governance basics right first will make a Data Mesh transition smoother when the time comes.
A practical starting point
If you checked most of the readiness criteria above, the recommended approach is to start with one domain rather than attempting an organization-wide rollout. Choose a domain that has strong business sponsorship, existing data expertise, and a use case with a clear, measurable outcome. Prove the model works there before expanding.
Once your first domain is running well, your data catalog becomes the connective tissue that makes the rest of the mesh discoverable and governable. Every domain's data products need to be findable, well-documented, and accessible to the rest of the organization. That is where a platform like OvalEdge fits in, helping teams catalog domain data products, apply consistent metadata, and manage access without creating a new centralized bottleneck.
What are the benefits of implementing Data Mesh?
Organizations are moving away from traditional data lakes because they create bottlenecks. Centralized data control can lead to slow decision-making and a disjointed understanding of data needs.
Data Mesh eliminates these challenges by decentralizing architecture and empowering domain-level autonomy.
Key benefits include:
- Reduced bottlenecks: Teams can operate independently without waiting on a central team.
- Faster insights: Each team manages and accesses data directly relevant to their function.
- Improved accountability: Data quality and governance are owned by domain experts.
- Scalable collaboration: Teams can share, consume, and build on each other’s data products.
It’s worth mentioning that if your current architecture already works effectively, adopting Data Mesh won’t automatically yield better results. These benefits primarily apply to organizations struggling with rigid data lake systems or seeking to modernize their data strategy.
Data Mesh Principles and Architecture
As noted earlier, Data Mesh operates on four foundational principles. These are interdependent; following all four ensures maximum efficiency and scalability.
Domain ownership
This principle often represents the largest cultural shift. Instead of a centralized team managing all enterprise data, each domain team takes responsibility for their data lifecycle.
This decentralization reduces reliance on dedicated data engineers and eliminates friction between teams and the data they use daily.
For example:
- If George from marketing needs web analytics, they no longer wait on IT.
- If developer Maggie needs debugging data, she can directly access relevant datasets.
However, with this freedom comes greater responsibility — teams must ensure data quality, compliance, and reliability within their own domains.
Data as a product
In a Data Mesh, data is treated as a product, not just a byproduct of operations.
Each data domain team becomes both a producer and a custodian. Their role extends to:
- Ensuring data is discoverable, understandable, and trustworthy.
- Designing access mechanisms that serve internal “data consumers.”
- Maintaining clear documentation and metadata for transparency.
This mindset shift enforces accountability and creates a consumer-friendly data ecosystem across the enterprise.
Self-serve data platforms
You might ask, “How do we enable all teams to build and manage their data products effectively?”
That’s where self-service data platforms come in.
A domain-agnostic platform team manages infrastructure and provides the tools, templates, and environments that domain teams use to deploy their products.
This principle empowers teams to:
- Build, test, and publish their own data products.
- Access analytics capabilities without deep technical expertise.
- Reduce dependency on IT or centralized data engineers.
It simplifies innovation while maintaining control, making domain autonomy sustainable and scalable.
Federated computational governance
Even in a decentralized setup, governance must be consistent. Federated governance ensures that standards and policies remain uniform across all domains.
This principle involves:
- Forming a governance council of domain and platform product owners.
- Defining global policies for interoperability, security, and compliance.
- Enforcing data quality, access control, and metadata consistency.
It strikes the right balance between local autonomy and global consistency, ensuring seamless cross-domain collaboration.
For a deeper look at how these two approaches differ structurally, see our breakdown of data mesh vs data fabric.
Data Mesh Logical Architecture
A Data Mesh architecture enables domain teams to perform cross-domain data analysis using self-service tools. Each domain maintains operational and analytical data, builds models, and creates products consumable by others.
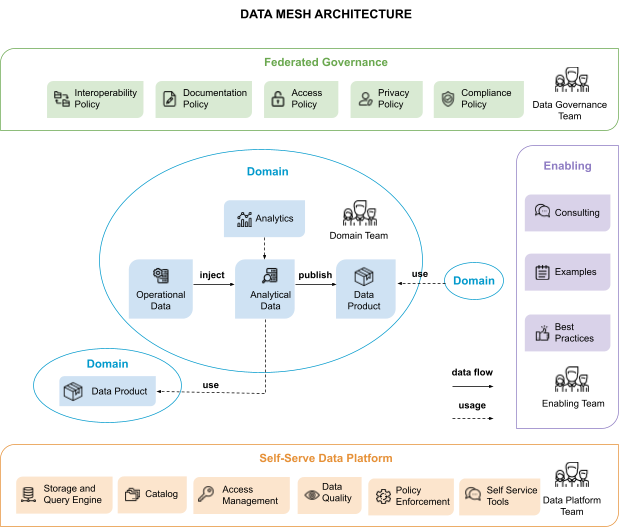
Teams collaborate to set global interoperability, documentation, and security standards through a federated governance framework.
An enabling team supports all domains by guiding them on modeling, platform usage, and product interoperability, ensuring smooth adoption of Data Mesh principles.
How do you create a Data Mesh using OvalEdge?
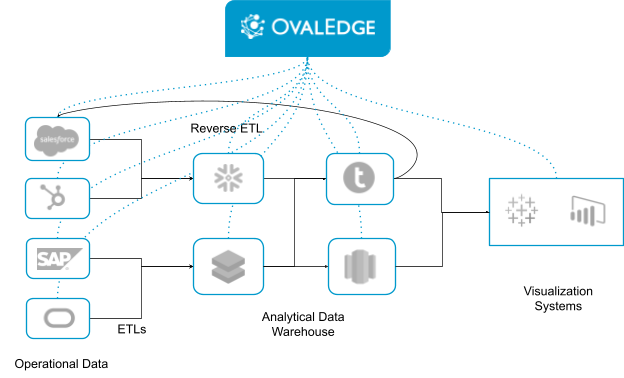
As much as we’d love to say you can simply install the Data Mesh plugin, and OvalEdge will do the rest for you, it’s not quite that simple. As I mentioned previously, this is an architecture, and can’t be solved by one tool. But OvalEdge can play a crucial role in solving the puzzle.
Here’s an example of how OvalEdge fits into your physical architecture:
Establish Federated Governance and Control it
Governance is at the heart of everything OvalEdge does, so establishing federated governance for your Data Mesh is as simple as possible. OvalEdge is a unified platform with Data Catalog, Access Management and various kinds of policy enforcement.
Using OvalEdge, you can easily manage and control the following policies.
- Privacy policies, which are dictated by various regulations like GDPR and CCPA
- Documentation policies, compliant with regulations like BCBS in the banking sector, and SOX for all public companies.
- Establish policies for confidential data.
- Establish locationality policy, which is dictated by locationality laws.
- Establish policies for secret data
- Standardization & documentation policies
Then once they’re established, you can monitor and control these policies within OvalEdge.
Build a self-service platform
Data Mesh doesn’t work unless everyone can find the data they need. OvalEdge makes it easy to build your own self-service platform. You can configure many data sources, and use it in a number of ways:
- Data Catalog: which allows everyone to easily find and understand the data at scale.
- Data Access Management: this allows you to maintain security, while also allowing end-users to access data from other domains using an approval process.
- Business Glossary: this allows you to standardize your documentation and apply it across the data.
- Collaborate on data with the right context.
- Analyze data using various tools like Querysheet and other third-party tools.
Establish Domain-based Teams
As we’ve discussed, splitting people into domain teams is a key part of Data Mesh. Once you’ve decided what these teams are, you can simply organize them into teams within OvalEdge. We also provide various ways to organize teams, by roles, by teams, etc.
This helps you assign people the right privileges, and make changes to the configuration in bulk.
Divide Data into Domain
Once you have your data sources and governance set up, you can divide your data into domains that match your team structure.
Following traditional data governance, you can ensure everyone has access to the data they need, while remaining compliant in every market you’re in.
Build new Data Products
Now your teams can work to create their data products, and start creating value for each other.
Working together in OvalEdge, it’s easy to organize the data into meaningful products, and share them.
Share & Collaborate
Colleagues can then share and collaborate on their data products within OvalEdge. Whether that’s within their domain team, or across teams.
At this point, you have the makings of an effective Data Mesh, where teams own and maintain their own data products. And teams can easily use each other's products to work towards a shared goal.
Integrate
When used alongside a data storage provider like Snowflake, OvalEdge is the perfect platform for managing your decentralized data across your domain teams.
We manage your orchestration layer, including data governance and data analytics. Another key part of OvalEdge is the Data Catalog. This brings all your datasets together, allowing you to mesh them, create relationships, etc.
Now, I’m not going to sit here and insist that you need OvalEdge if you want to implement an effective Data Mesh architecture.
But what I can say is that we make it a whole lot easier!
Why Choose OvalEdge for Data Mesh Implementation?
While no single tool can “do” Data Mesh, OvalEdge streamlines every aspect of it from governance to access control to collaboration. The platform provides federated visibility, compliance automation, and data discovery, all critical enablers of a scalable Data Mesh.
To see how easily you can modernize your architecture:
👉 Request a Data Mesh Demo and experience how OvalEdge simplifies governance and enables autonomy.
Frequently Asked Questions
- What is Data Mesh in simple terms?
Data Mesh is a decentralized approach to managing and analyzing data where each business domain owns and governs its own data, treating it as a product that other teams can use. - What are the four key principles of Data Mesh?
They are: Domain Ownership, Data as a Product, Self-Serve Data Platform, and Federated Computational Governance. - How does OvalEdge support Data Mesh implementation?
OvalEdge helps by providing data cataloging, access management, policy enforcement, and governance tools to build and manage federated data systems efficiently. - What is the difference between Data Mesh and Data Lake?
A Data Lake is a centralized repository where raw data from across the organization is stored and managed by a central team. Data Mesh takes the opposite approach — it distributes data ownership to individual business domains, so each team manages and serves its own data products. The key difference is not just technical architecture but organizational accountability. A Data Lake centralizes both the data and the responsibility for it. Data Mesh decentralizes both. - Is Data Mesh only for large enterprises?
Data Mesh works best for organizations with multiple distinct business domains, each generating significant analytical data independently. That typically means mid-to-large enterprises. Smaller organizations with simpler data needs usually get faster results from a well-managed data warehouse or data lakehouse, which carry far less organizational overhead. If your central data team is not yet a bottleneck, Data Mesh is likely premature. - How long does a Data Mesh implementation take?
There is no fixed timeline, but most enterprise implementations run across multiple years. A realistic approach starts with a single domain pilot over three to six months, uses that to prove value and refine the model, then expands domain by domain. Organizations that attempt an organization-wide rollout from the start tend to struggle with coordination overhead and change management. Treating it as a phased program rather than a one-time project leads to better outcomes. - What is the role of a data catalog in a Data Mesh?
A data catalog is what makes a Data Mesh discoverable and usable across the organization. Each domain produces its own data products, but without a catalog, other teams have no reliable way to find, understand, or trust those products. The catalog provides the metadata, lineage, and documentation that connect decentralized data products into a coherent, searchable mesh. Without it, domain autonomy creates fragmentation instead of collaboration. - What is federated computational governance in Data Mesh?
Federated computational governance is one of the four core principles of Data Mesh. It means that governance policies are defined globally but enforced locally at the domain level, ideally through automated rules rather than manual review. Each domain follows the same standards for data quality, access control, and compliance, but applies them to its own data products independently. This balances domain autonomy with the consistency the organization needs for trust and regulatory compliance. - Can Data Mesh and Data Fabric work together?
Yes. Data Mesh and Data Fabric are not mutually exclusive. Data Mesh defines how data ownership and responsibility are organized across domains. Data Fabric is more of a technology layer that connects disparate data sources through automation and metadata. Some organizations use a Data Fabric architecture to provide the connective infrastructure that supports a Data Mesh operating model. The two complement each other when the organizational and technical goals are aligned.
What you should do now
|
Deep-dive whitepapers on modern data governance and agentic analytics

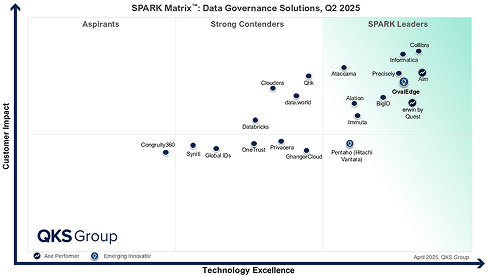
OvalEdge Recognized as a Leader in Data Governance Solutions
3ff1.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
aef2.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.