


Data quality has become harder to manage as organizations depend on shared data across analytics, AI, and cloud platforms. Modern data quality solutions move beyond reactive fixes by continuously profiling, validating, and monitoring data across the lifecycle. The 2026 landscape spans enterprise platforms, AI-driven observability tools, and engineering-focused frameworks. OvalEdge shows how data quality can be embedded within a broader governance and data intelligence layer rather than treated as a standalone function. When quality, governance, and observability work together, organizations can trust their data and make decisions with greater confidence.
Across many organizations, teams rely on the same data to answer basic business questions, yet the answers often do not align. Finance reports one number, dashboards show another, and AI models behave unpredictably. Meetings that should drive decisions instead focus on tracing data discrepancies.
This problem rarely stems from a lack of technology.
More often, it is due to poor data quality.
As data environments expand across cloud warehouses, transformation layers, and analytics tools, even small inconsistencies can quickly cascade into broken dashboards and delayed decisions. Manual checks and static rules struggle to keep pace.
Modern data quality solutions address this by automating profiling, validation, and monitoring across the data lifecycle, enabling organizations to manage quality as a continuous, operational capability rather than a reactive fix.
To evaluate which tools are best suited for this role, it is important first to understand what data quality solutions are designed to do and how they differ from earlier approaches.
What are data quality solutions?
Data quality solutions are software platforms that ensure data remains accurate, complete, and consistent as it moves through analytics, AI, and operational systems.
Rather than fixing errors after they appear, these platforms continuously evaluate data during ingestion, transformation, and consumption to maintain trust in business outputs.
Modern data quality solutions operate across the full data lifecycle, detecting issues early and providing context on impact and root cause. Unlike legacy tools, they adapt to schema changes, new data sources, and evolving logic by using automation, metadata, and observability instead of static rules.
Core functions of data quality solutions
At their core, most enterprise data quality solutions focus on a consistent set of capabilities that work together rather than in isolation.
-
Data profiling examines structure, distributions, and patterns to establish a baseline understanding of the data and surface unexpected changes early.
-
Data validation applies rules, constraints, and thresholds to ensure values meet technical and business expectations.
-
Data cleansing and standardization correct common issues such as formatting errors, duplicates, and inconsistent representations.
-
Continuous monitoring tracks quality metrics over time and alerts teams when accuracy, completeness, or freshness degrades.
-
Root cause analysis uses lineage, metadata, and freshness signals to trace issues back to their source and assess downstream impact.
When these functions operate together, data quality shifts from a reactive cleanup exercise to a proactive control layer. Teams gain earlier visibility, faster resolution, and clearer accountability for data issues that affect analytics, AI models, and regulatory reporting.
With a clear view of what data quality solutions are designed to do, it becomes easier to evaluate the leading platforms available in 2026 and understand how they compare across enterprise, AI-driven, and engineering-focused use cases.
|
If you want a deeper look at how these capabilities come together in real enterprise environments, our Data Quality whitepaper breaks down practical architectures, governance models, and examples from modern data teams. |
Best data quality solutions in 2026
The data quality market in 2026 reflects how much enterprise data environments have changed.
Organizations now manage cloud warehouses, real-time pipelines, analytics platforms, and AI workflows at the same time. As a result, data quality solutions have evolved in different directions.
Below is a breakdown of leading data quality solutions, highlighting their key services and strengths based on how they position themselves publicly.
Best enterprise data quality solutions
Enterprise data quality solutions are built for large, complex environments where quality must scale across systems, teams, and governance requirements. The following platforms are commonly evaluated for enterprise-wide data quality needs.
1. OvalEdge
OvalEdge is a data governance platform built from the ground up with AI-driven data quality, validation, and profiling as core capabilities. Data quality is natively embedded within the platform alongside metadata management, end-to-end lineage, data observability, and policy enforcement, rather than added as a patch solution.
This design supports consistent quality controls across complex, enterprise-scale data environments.
Key services and strengths
-
Automated data profiling
Continuously analyzes datasets to establish baselines and surface unexpected changes in structure or completeness.
-
Data validation and quality checks
Applies business and technical rules to ensure data meets defined expectations across analytics and reporting workflows.
-
End-to-end data lineage
Traces data from source to consumption, enabling faster root cause analysis and impact assessment.
-
Data observability and monitoring
Monitors data health over time, helping teams detect quality issues before they affect downstream users.
-
Governance and policy enforcement
Aligns data quality with ownership, access controls, and compliance requirements to support auditability.
This integrated approach makes OvalEdge a strong fit for enterprises that need scalable data quality capabilities tightly aligned with governance and data intelligence.
2. Informatica
Informatica provides enterprise data quality capabilities as part of its broader cloud data management platform. Its data quality offerings focus on helping organizations assess, improve, and maintain data accuracy and consistency across complex, distributed environments.
These capabilities are integrated with metadata management, governance, and master data management within the Informatica Intelligent Data Management Cloud.
Key services and strengths
-
Advanced data profiling
Analyzes data structure, patterns, and value distributions to surface inconsistencies and anomalies before quality rules are applied.
-
Data cleansing and standardization
Supports parsing, matching, deduplication, and standardization to resolve inconsistencies across customer, product, and reference data.
-
Rule-based data validation
Enables definition and enforcement of business and technical rules to ensure data conforms to expected formats and thresholds.
-
Stewardship and remediation workflows
Provides workflows for reviewing exceptions, managing remediation, and assigning accountability for ongoing quality improvement.
-
Integration with governance and compliance controls
Connects data quality processes with metadata, lineage, and policy enforcement to support auditability and regulatory reporting.
Limitations
-
Customers often note that Informatica’s data quality capabilities are complex and costly to implement, particularly in large environments.
-
Reviews frequently mention that onboarding and configuration require significant expertise, which can slow time-to-value for teams without dedicated data governance resources.
As a result, Informatica is best suited for large enterprises with mature governance programs, dedicated resources, and complex compliance needs, where centralized control outweighs slower time-to-value.
3. Talend
Talend offers data quality capabilities as part of its broader data integration and management platform. This tool is designed to help organizations profile, cleanse, and validate data as it moves through ingestion and transformation workflows.
Data quality functions are closely integrated with Talend’s ETL, pipeline orchestration, and data preparation tools, enabling quality checks to be applied early and consistently across the data lifecycle.
Key services and strengths
-
Data profiling during ingestion
Analyzes structure, patterns, and completeness of incoming data to identify quality issues before transformation and loading.
-
Data cleansing and standardization
Provides built-in routines for correcting formats, removing duplicates, and standardizing values across datasets.
-
Rule-based validation within pipelines
Supports business and technical rules that can be applied directly within ETL and transformation workflows.
-
Integration with data integration and orchestration
Embeds quality checks into data pipelines, reducing the need for separate quality tooling and manual handoffs.
-
Support for cloud and hybrid environments
Works across on-premise, cloud, and hybrid architectures, aligning quality processes with distributed data environments.
Limitations
Talend users commonly point out that data quality features are closely tied to ETL workflows, which can limit visibility outside ingestion and transformation stages. Customer feedback also highlights that deeper governance and observability capabilities may require additional tooling or customization.
These considerations make Talend a fit for organizations that want data quality tightly integrated with ingestion and transformation workflows, particularly when engineering teams own pipelines end-to-end and governance requirements are lighter.
Best augmented and AI-powered data quality platforms
Augmented and AI-powered data quality platforms focus on automated detection, monitoring, and prioritization of data issues in dynamic analytics environments. The following solutions are often considered for data quality use cases that rely on automation and continuous monitoring.
4. Monte Carlo
Monte Carlo provides a data observability platform that helps teams detect, understand, and resolve data reliability issues in modern analytics environments. The platform monitors data behavior across cloud data warehouses, transformation tools, and downstream analytics to surface unexpected changes before they impact business users.
Monte Carlo’s approach centers on automated detection and impact awareness rather than manual rule creation.
Key services and strengths
-
Automated anomaly detection
Continuously monitors data freshness, volume, distribution, and schema changes to identify anomalies without extensive manual configuration. -
End-to-end monitoring across the analytics stack
Observes data as it moves from ingestion through transformation to consumption, providing visibility across pipelines and dashboards. -
Impact analysis and alerting
Maps data issues to affected tables, dashboards, and reports, helping teams prioritize incidents based on downstream impact.
-
Root cause analysis support
Uses metadata and pipeline context to help teams trace issues back to their source more quickly. -
Warehouse-native integrations
Integrates directly with modern cloud data warehouses and transformation tools, minimizing operational overhead.
Limitations
Monte Carlo is often praised for detection and alerting, but reviews note that it is less focused on remediation and governance workflows. Teams may still need complementary tools for ownership management, policy enforcement, and standardized quality rules across domains.
Given this focus, Monte Carlo is used by teams prioritizing early detection and reliability in analytics environments, while relying on complementary tools for governance, remediation, and ownership management.
5. Bigeye

Bigeye provides a data observability platform designed to help organizations monitor and maintain data quality across modern cloud data environments. It focuses on automated quality measurement and anomaly detection directly within data warehouses, allowing teams to understand data health without extensive manual rule creation.
The platform emphasizes visibility into data behavior as it changes over time.
Key services and strengths
-
Automated data quality metrics
Continuously measures key quality dimensions such as freshness, volume, distribution, and completeness across datasets.
-
Machine learning–based anomaly detection
Establishes baselines using historical data patterns and flags deviations that may indicate quality issues.
-
Warehouse-native monitoring
Operates directly on cloud data warehouses, reducing data movement and simplifying deployment.
-
Quality scorecards and reporting
Provides aggregated views of data health that help teams track trends and identify recurring issues. -
Integration with analytics workflows
Connects quality metrics to downstream analytics assets, improving visibility into how data issues affect reporting and analysis.
Limitations
Customer feedback frequently mentions that while Bigeye excels at monitoring metrics, defining business-context validation and ownership models can require additional setup. Some users also note that deeper governance alignment depends on integrations rather than native controls.
As a result, Bigeye is often evaluated by analytics teams seeking continuous visibility into data health, with the understanding that deeper governance alignment may depend on integrations rather than native controls.
6. Soda
Soda provides a data quality monitoring platform designed to help teams test, monitor, and validate data in modern cloud data environments. Soda focuses on combining automated anomaly detection with rule-based checks, allowing teams to monitor data quality continuously while retaining control over explicit validation logic.
The platform is built to work closely with cloud data warehouses and analytics workflows.
Key services and strengths
-
Automated anomaly detection
Continuously monitors metrics such as freshness, volume, and distribution to detect unexpected changes without relying solely on manual rules. -
Rule-based data quality checks
Enables teams to define explicit quality rules using checks-as-code, supporting clear expectations and repeatable validation. -
Cloud-native integrations
Integrates directly with modern cloud data warehouses and analytics platforms, supporting scalable monitoring with minimal overhead. -
Continuous monitoring and alerting
Tracks data quality over time and notifies teams when thresholds are breached or anomalies are detected. -
Support for engineering workflows
Aligns with CI/CD and pipeline-based processes, making it easier to embed quality checks into data engineering workflows.
Limitations
Soda users often highlight the flexibility of checks-as-code, but reviews note that rule creation and maintenance can become manual at scale. As environments grow, teams may need stronger automation and prioritization to reduce alert fatigue.
These trade-offs make Soda a strong option for engineering-driven teams that value flexibility and checks-as-code, provided they can manage rule maintenance and alert prioritization as data environments scale.
While these platforms focus on continuous monitoring and automated detection, some teams prefer more direct control over how data quality rules are defined and enforced within engineering workflows.
Best data profiling and validation tools
Data profiling tools and validation tools focus on defining, testing, and enforcing data quality rules directly within data pipelines and engineering workflows. The following tools are commonly used to establish baselines and validate data at scale.
7. AWS Deequ
AWS Deequ is an open-source data quality and validation library developed by Amazon and designed for large-scale data processing environments. Deequ enables teams to define, measure, and validate data quality constraints directly on datasets processed with Apache Spark.
Rather than functioning as a standalone platform, it is intended to be embedded into data engineering workflows and pipelines.
Key services and strengths
-
Constraint-based data validation
Allows teams to define explicit data quality constraints such as completeness, uniqueness, value ranges, and statistical thresholds, and automatically evaluate datasets against them. -
Scalable data profiling
Computes descriptive statistics and distributions across large datasets, making it suitable for high-volume batch processing in Spark environments. -
Integration with Spark pipelines
Runs natively within Apache Spark jobs, enabling data quality checks to be executed as part of existing ETL and batch workflows without additional infrastructure. -
Verification and metrics reporting
Produces detailed metrics and validation results that can be logged, persisted, or integrated into monitoring systems for trend analysis. -
Engineering-first flexibility
Provides full control through code, making it well-suited for teams that prefer programmatic quality checks embedded into data pipelines rather than GUI-driven platforms.
Limitations
AWS Deequ is powerful for Spark-based validation, but users consistently point out that it is engineering-heavy and lacks a user interface, lineage, or governance layer. Non-technical stakeholders typically require additional tooling to interpret results.
Accordingly, AWS Deequ is best suited for Spark-centric engineering teams that prefer programmatic control over data quality checks and are comfortable operating without a native UI or governance layer.
8. Great Expectations

Great Expectations is an open-source data quality framework designed to help teams define, validate, and document data quality expectations directly within data workflows. The framework enables organizations to create explicit, human-readable expectations about data and automatically validate datasets against them as data moves through pipelines.
Key services and strengths
-
Expectation-based data validation
Allows teams to define clear expectations for data quality, such as schema consistency, value ranges, and null thresholds, and automatically test datasets against them. -
Data profiling and expectation generation
Provides tools to profile datasets and generate suggested expectations, helping teams establish initial quality baselines more efficiently. -
Integration with data pipelines and orchestration
Integrates with orchestration tools and ETL workflows, enabling quality checks to run as part of scheduled jobs and CI/CD processes.
-
Data documentation and transparency
Generates human-readable data documentation that explains expectations, validation results, and quality status, improving visibility for both technical and non-technical users.
-
Flexible deployment across data platforms
Supports a wide range of data sources, including cloud warehouses, databases, and file-based systems, making it adaptable to diverse data stacks.
Limitations
Great Expectations is valued for transparency, yet reviews often mention that expectation management can become difficult as datasets scale. Without centralized governance or automation, maintaining consistency across teams can require significant coordination.
As a result, Great Expectations is commonly adopted in environments where teams want transparent, test-driven data validation, with the understanding that governance and coordination become more challenging as usage scales.
Together, these profiling and validation tools illustrate how data quality can be enforced directly within engineering workflows.
To evaluate platforms more broadly, it is important to step back and look at the core capabilities that modern data quality solutions must provide to operate effectively at enterprise scale.
|
Also Read → How to set up a data governance team for success |
Key capabilities modern data quality platforms must have
As data environments grow in size and complexity, basic checks and one-time validations stop being effective. Modern data quality solutions are expected to run continuously, adapt to change, and provide enough context for teams to act quickly.
Regardless of platform type, several capabilities consistently distinguish scalable data quality solutions from basic tooling.
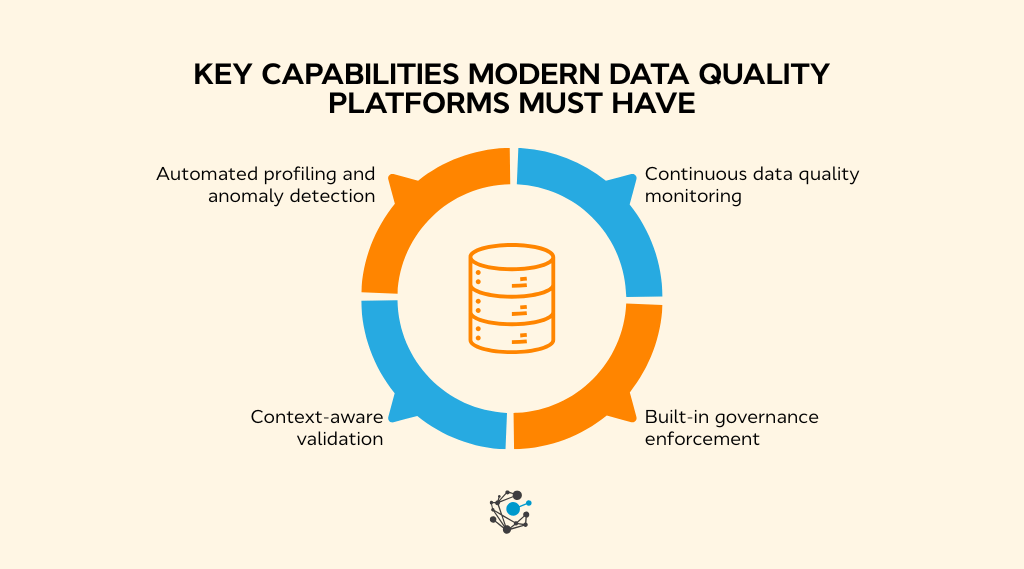
Automated data profiling and anomaly detection
Automated data profiling allows platforms to understand normal data behavior without relying solely on manual rules. By continuously analyzing structure, distributions, and patterns, modern tools establish baselines and detect unexpected changes as data evolves. This capability is critical in fast-changing environments, where manual maintenance does not scale.
A CDO Insights 2024 report shows that of 600 data leaders, 42% cite data quality as the top data-related obstacle to adopting generative AI and LLMs, reinforcing the need for automated profiling, testing, and observability.
Continuous data quality monitoring and observability
Modern data quality is not a point-in-time activity. Continuous monitoring provides ongoing visibility into freshness, completeness, and consistency as data moves through pipelines and into downstream systems. Observability helps teams understand not only when data breaks, but also how often and why.
Continuous monitoring is a requirement for maintaining trust in enterprise analytics and AI initiatives, particularly in distributed cloud environments where data changes frequently.
Context-aware validation using metadata and lineage
Validation becomes far more effective when informed by context. Metadata and lineage provide insight into where data originates, how it is transformed, and which reports or models depend on it. This allows teams to assess the real impact of quality issues rather than treating every failure as equally urgent.
Lineage-driven validation also accelerates root cause analysis by narrowing investigations to upstream sources. This approach aligns with guidance from Deloitte, which emphasizes contextual data controls as critical for scalable analytics and regulatory reporting.
Built-in governance and policy enforcement
Data quality cannot be separated from governance. Built-in policy enforcement ensures that quality checks align with data ownership, access controls, and compliance requirements, which is especially important in regulated environments where auditability and traceability are mandatory. This pressure becomes most visible during reporting cycles.
In Deloitte’s 2024 “Sustainability Action Report on reporting readiness, 57% of respondents cited data quality as their top challenge, and 88% ranked it among their top three, showing how quickly quality issues turn into reporting bottlenecks.
Unified data quality, observability, and governance
Modern platforms increasingly combine data quality, observability, and governance into a single operating layer. Quality checks are informed by pipeline behaviour and usage context, while governance policies directly shape how data is validated and monitored. This convergence reduces tool fragmentation, improves response times, and makes data quality a shared, operational responsibility rather than a standalone process.
Together, these capabilities allow data quality platforms to function as an operational control layer rather than a reactive cleanup tool. They provide the automation, visibility, and context required to support reliable analytics, AI workflows, and compliance reporting in enterprise-scale data environments.
With these core capabilities in mind, the next step is understanding how organizations can evaluate and choose the right data quality solution based on their architecture, maturity, and long-term objectives.
How to choose the right data quality solution?
Choosing a data quality solution is not about feature breadth alone. It requires matching platform capabilities to how data actually flows, changes, and is governed across the organization.
As data estates grow more distributed, quality tooling must support scale, automation, and accountability without adding operational friction.

Assess your data scale, architecture, and complexity
Data quality tools must operate within the realities of the data architecture. Volume, velocity, and variety matter. Platforms that work well in small analytics environments often struggle when applied to enterprise-scale pipelines spanning multiple cloud systems.
Industry guidance consistently highlights this mismatch as a root cause of failed quality initiatives. An overview published by CIO explains how data quality challenges intensify as organizations scale cloud and analytics architectures, especially when tooling is not designed for distributed environments.
Prioritize automation and AI-driven capabilities
Manual rule creation does not scale in environments where schemas, sources, and usage patterns change frequently. Automated profiling and anomaly detection reduce the burden on teams while improving early detection of issues.
Automation significantly reduces the time required to identify and respond to data incidents in modern data stacks.
Evaluate governance, security, and compliance support
Data quality and governance are tightly connected. Quality checks must align with data ownership, access controls, and audit requirements, particularly in regulated industries. When these elements are disconnected, quality issues become harder to trace and resolve.
Integrating data quality with governance frameworks improves consistency, transparency, and regulatory confidence as analytics usage expands.
Check integration with your existing data stack
Strong integration reduces operational overhead. A data quality solution should work naturally with existing warehouses, transformation tools, orchestration frameworks, and analytics platforms. Poor integration often results in partial visibility and duplicated effort.
Platforms that integrate with metadata and lineage systems provide additional context, helping teams understand where issues originate and which downstream assets are affected.
Compare usability for engineers and business users
Adoption depends on usability across roles. Engineers need programmatic access and pipeline integration, while business users and data owners need visibility into quality status and accountability. Tools that serve only one audience tend to create silos rather than shared ownership.
Clear reporting, ownership attribution, and accessible dashboards help make data quality a shared responsibility rather than a specialized task.
Understand pricing, scalability, and long-term ROI
Pricing models vary widely. Some platforms scale by data volume, others by number of assets, checks, or users. Understanding how costs grow alongside data usage is essential.
Multiple studies highlight that organizations reduce long-term costs when data quality issues are detected earlier and handled through automated controls rather than downstream rework.
Taken together, these considerations show that the way data quality is managed has a direct impact on cost, efficiency, and trust in data across the organization.
Conclusion
Data quality often stays in the background until it creates visible problems. Reports stop aligning, dashboards lose credibility, and teams spend more time explaining numbers than acting on them. These issues are not inevitable. With the right data quality solutions, quality can be managed continuously instead of through repeated fixes.
The platforms covered in this guide reflect different approaches to data quality, from enterprise governance and control to automated monitoring and engineering-led validation. The right choice depends on how data is produced, shared, and governed across the organization.
Sustainable data quality comes from connection. When profiling, validation, monitoring, and governance work together, teams gain clearer visibility, resolve issues faster, and rebuild trust in analytics and AI outputs.
So the question is, how confident is your organization in the data being used every day?
If improving that confidence is a priority, consider booking a demo with the OvalEdge team to see how an integrated data quality and governance platform can support enterprise-scale data needs.
FAQs
1. What are data quality solutions used for?
Data quality solutions are used to automatically profile, validate, monitor, and improve data accuracy, completeness, and consistency across analytics, AI, and compliance workflows.
2. How are data quality solutions different from data observability tools?
Data quality solutions enforce rules and standards, while data observability tools focus on detecting unexpected changes in data behavior, such as freshness or volume issues. Many modern platforms combine both.
3. Do enterprises need AI-powered data quality solutions?
AI-powered data quality solutions help enterprises scale by reducing manual rule creation, detecting anomalies automatically, and prioritizing issues based on business impact.
4. Can data quality solutions work with cloud data warehouses?
Yes. Most modern data quality solutions integrate directly with cloud warehouses like Snowflake, BigQuery, and Redshift without moving data.
5. How long does it take to implement a data quality solution?
Implementation typically ranges from a few days to a few weeks, depending on data complexity, integrations, and governance requirements.
Deep-dive whitepapers on modern data governance and agentic analytics

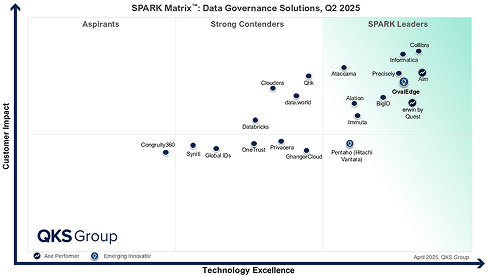
OvalEdge Recognized as a Leader in Data Governance Solutions
3ff1.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
aef2.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.