


Modern data architectures increasingly rely on streaming pipelines and event-driven systems that process data continuously. In these environments, traditional lineage approaches that document pipelines after execution often fail to provide timely visibility into data dependencies. Real-time data lineage tracking enables teams to monitor data movement as it occurs, allowing faster impact analysis, proactive issue detection, and improved pipeline reliability. By combining metadata capture, dependency graphs, and observability signals, organizations can better understand how data flows across distributed systems. Implementing real-time lineage helps teams maintain trust in analytics while supporting scalable and resilient data operations.
Monday morning dashboards are supposed to bring clarity. Instead, we sometimes see conflicting numbers across finance, sales, and analytics. The immediate question becomes familiar to every data team: where did the data change?
In traditional batch environments, we could wait for the next scheduled run, inspect logs, and trace the transformation path afterward. In streaming architectures, that approach breaks down because pipelines run continuously and errors propagate before teams even realize something is wrong.
The scale of this challenge is growing quickly.
According to the 2024 Data Streaming Report by Confluent, based on a global survey of more than 4,000 IT leaders, 86% say data streaming is a strategic priority for their organizations.
As a result, real-time data lineage tracking has shifted from a governance convenience to an operational requirement. Static lineage documentation cannot keep up with streaming pipelines, CDC flows, and event-driven systems.
In this guide, we explore how real-time lineage works, why it matters for modern architectures, and how teams can implement it to improve reliability and visibility across distributed data environments.
What is real-time data lineage tracking?
Real-time data lineage tracking captures and visualizes how data moves across systems as it flows through pipelines. Instead of documenting transformations after jobs finish, it continuously monitors dependencies, transformations, and metadata changes across both streaming and batch environments.
This immediate visibility helps teams quickly understand how upstream changes affect downstream systems. As a result, organizations can perform faster impact analysis, detect pipeline issues earlier, and maintain reliable data across dashboards, applications, and analytics platforms.
Unlike traditional lineage tools that generate snapshots after execution, real-time lineage monitoring tracks pipelines while they are running. This is especially important in streaming environments where data flows continuously, and pipelines rarely have a defined completion point.
Real-time lineage vs traditional batch and static lineage
Traditional lineage tools document data movement after execution. Real-time data lineage tracking continuously monitors streaming and batch pipelines as changes occur. The difference comes down to timing, monitoring depth, and operational impact.
|
Feature |
Real-Time Lineage |
Traditional / Batch Lineage |
|
Update frequency |
Continuous |
Periodic |
|
Monitoring model |
Live tracking |
Snapshot-based |
|
Use case |
Streaming analytics, event-driven systems |
Static reporting, audit documentation |
|
Impact analysis |
Immediate |
Delayed |
|
Operational value |
Proactive issue detection |
Post-failure investigation |
The shift from static to real-time lineage fundamentally changes how organizations manage data operations. Instead of using lineage primarily for documentation or audits, teams gain continuous visibility into how pipelines behave.
This transforms lineage from a passive map of data movement into an operational tool that supports monitoring, troubleshooting, and more reliable data operations.
|
Related Reading: For readers exploring modern tooling options, can also review this Ovaledge guide on AI-Powered Open Source Data Lineage Tools, which highlights how modern platforms automate lineage tracking and metadata discovery across distributed data environments. |
Core components of live data lineage systems
Effective live data lineage systems rely on several capabilities that enable continuous tracking and visibility across modern data environments.
-
Streaming metadata capture: Captures metadata directly from pipelines as data flows through them. This keeps lineage information updated with the latest sources, schemas, and transformations.
-
Event-driven lineage updates: Updates lineage graphs automatically whenever a pipeline event occurs. Changes such as schema updates or transformation edits appear in the lineage instantly.
-
Continuous pipeline observability: Combines lineage with pipeline monitoring to show how data flows and how pipelines are performing. This helps teams quickly identify delays, failures, or unusual activity.
-
Column-level dynamic tracking: Tracks how individual fields move and transform across pipelines. This makes it easier to see exactly which columns are affected when upstream changes happen.
Together, these components allow lineage systems to update continuously and provide clear visibility into modern data pipelines.
How real-time data lineage powers modern streaming and event-driven architectures
Modern data environments run on streaming pipelines, microservices, and near-real-time dashboards. Streaming data lineage gives teams continuous visibility across those systems by capturing metadata at execution time instead of after the fact.
This real-time visibility allows organizations to monitor data movement, understand dependencies instantly, and detect issues before they affect downstream analytics.
|
Pro-Tip: Many modern data platforms, including governance solutions such as OvalEdge, support these capabilities by combining metadata capture, lineage graphs, and pipeline observability within a unified data governance layer. |
Supporting streaming pipelines and event-driven systems
Streaming architectures include event brokers, CDC pipelines, real-time analytics platforms, and microservices where data flows continuously between systems. Unlike batch environments, these pipelines process events instantly, which makes it important to track data movement in real time.
Real-time lineage helps teams follow how updates move across these pipelines. When database changes stream into analytics systems, lineage tracking shows how inserts, updates, and deletes travel through the architecture and impact downstream dashboards or applications.
How live metadata capture works across streaming layers
Live lineage systems capture metadata from multiple stages of the data pipeline. At the broker level, metadata includes details such as topics, partitions, and schemas that show how data enters and moves through streaming systems.
Metadata is also captured during transformations where data is filtered, joined, or aggregated. Event-driven APIs send these updates to a lineage engine so dependency graphs refresh automatically as pipeline changes occur.
Live dependency graph generation and column-level propagation
Once metadata is collected, lineage systems generate dependency graphs that map how datasets, tables, and pipelines are connected. In real-time environments, these graphs update continuously as data flows through pipelines.
Column-level propagation adds deeper visibility by tracking how individual fields move across transformations. If a column changes upstream, teams can instantly see which downstream tables, reports, or dashboards depend on that field.
|
Pro-Tip: Many modern data platforms, including governance solutions such as OvalEdge, support these capabilities by combining metadata capture, lineage graphs, and pipeline observability within a unified data governance layer. |
Essential capabilities for effective real-time data lineage tracking
Not every lineage solution can handle continuously running data environments. For real-time lineage monitoring to work effectively in production, organizations need capabilities that support streaming metadata, dynamic dependency tracking, and operational monitoring across pipelines.
![]()
1. Streaming metadata capture
Streaming metadata capture collects metadata directly from pipelines such as Kafka streams, CDC systems, and real-time processing engines. This allows teams to observe how data moves across systems while pipelines are running instead of relying on delayed metadata scans.
Without streaming metadata capture, lineage quickly becomes outdated in fast-moving environments. Many modern governance platforms enable this through broker listeners, connectors, and metadata APIs that automatically record pipeline activity.
|
Related resource: OvalEdge explains in its guide, Data Lineage Best Practices for 2026, how real-time metadata collection helps improve lineage accuracy and keeps data dependencies up to date in streaming environments. |
2. Event-driven lineage updates
Real-time lineage systems should update dependency graphs whenever a pipeline event occurs. When a schema changes, a transformation is modified, or a new data source is introduced, the lineage graph should reflect that change immediately.
Event-driven updates eliminate the delays that occur when lineage systems rely on periodic metadata refreshes. This ensures that teams working on analytics, reporting, or data governance always see the most current dependency relationships across pipelines.
3. Column-level dynamic lineage tracking
Column-level lineage provides detailed visibility into how individual fields move and transform across pipelines. Instead of showing only table-level relationships, dynamic lineage tracking identifies exactly which columns influence downstream datasets, reports, or metrics.
This level of visibility is essential for accurate impact analysis and governance.
|
Do you know: OvalEdge demonstrates this capability in its article How OvalEdge Supports Column-Level Lineage With Dremio, where the platform builds column-level lineage by parsing Dremio queries and mapping how fields move between datasets and views. |
This approach helps teams trace how specific fields propagate across transformations and downstream assets.
4. Continuous monitoring dashboards
Lineage becomes significantly more useful when it is combined with operational visibility. Continuous monitoring dashboards display live dependency graphs, pipeline status, recent changes, and data quality signals in a centralized interface.
This helps data teams understand not only how data moves but also how pipelines are performing. Platforms that integrate lineage with monitoring allow teams to quickly detect pipeline failures, latency issues, or unexpected schema changes before they affect downstream analytics.
5. Automated impact analysis
Automated impact analysis allows teams to quickly identify downstream dependencies when a change occurs upstream. Instead of manually tracing pipelines, the lineage system automatically highlights affected datasets, reports, dashboards, and consumers.
This capability is particularly valuable during schema updates, transformation changes, or pipeline failures. Automated lineage traversal helps teams assess the impact of changes quickly and take corrective action before business users experience inaccurate or delayed analytics.
Implementation framework: how to enable real-time lineage tracking
Implementing real-time data lineage tracking requires more than enabling a feature in a lineage tool. Organizations must align streaming architecture, metadata capture, observability, and governance processes so that lineage updates continuously as data flows through pipelines.
The framework below outlines practical steps teams can follow to operationalize live lineage tracking across modern data environments.
![]()
Step 1: Map streaming and batch pipeline inventory
The first step is creating a clear inventory of all pipelines across the data ecosystem. Without a complete view of data movement, lineage graphs will contain gaps that hide dependencies and operational risks.
Start by documenting all major data pipelines, including:
-
Streaming pipelines: Identify event-driven pipelines that process real-time data through brokers and stream processors.
-
CDC pipelines: Capture database change streams that move updates into analytics or operational systems.
-
ETL or ELT workflows: Document batch transformations that load data into warehouses or lakehouses.
-
Analytics dashboards and reports: Track downstream assets such as dashboards, metrics layers, and BI tools.
This inventory should map the full flow of data from source systems to analytics consumption layers.
Step 2: Enable streaming metadata capture
Once pipelines are mapped, the next step is enabling automated metadata capture from streaming systems. Metadata must update continuously so lineage graphs reflect the current pipeline state.
Common approaches for streaming metadata capture include:
-
Broker-level listeners: Capture metadata from event brokers to record topics, partitions, and schema updates.
-
Metadata capture APIs: Use APIs to collect metadata events directly from streaming and processing platforms.
-
Pipeline connectors: Connect lineage tools to ingestion and transformation systems to track pipeline activity.
-
Transformation engine hooks: Record joins, filters, and aggregations as transformations execute.
When implemented properly, schema or transformation changes should automatically update lineage graphs.
Step 3: Deploy a dynamic lineage graph engine
A lineage graph engine converts metadata into dependency relationships across pipelines, datasets, and reports. This engine continuously updates the lineage graph as pipeline events occur.
Key capabilities a lineage engine should support include:
-
Dynamic dependency graph updates: Continuously refresh lineage graphs as pipeline changes occur across systems.
-
Column-level lineage tracking: Trace how individual fields move through transformations and influence downstream assets.
-
Cross-platform pipeline visibility: Aggregate lineage across databases, streaming platforms, warehouses, and BI tools.
-
Real-time dependency mapping: Instantly show upstream and downstream relationships when data changes occur.
|
Practical Insight: Platforms such as OvalEdge provide visual lineage graphs that allow teams to explore upstream and downstream dependencies across datasets and pipelines.
|
The lineage graph becomes the operational map for understanding data movement across the organization.
Step 4: Integrate data quality and observability layers
Lineage becomes significantly more valuable when combined with pipeline observability and data quality monitoring. This integration helps teams detect issues and quickly trace their root causes.
Important signals that should integrate with lineage include:
-
Data freshness checks: Monitor whether datasets update within expected time windows.
-
Schema drift detection: Identify structural changes in datasets that could break downstream pipelines.
-
Pipeline latency alerts: Detect delays in streaming pipelines or transformation workflows.
-
Validation rule failures: Trigger alerts when data quality checks fail during ingestion or transformation.
When these signals connect to lineage graphs, teams can immediately identify the upstream pipeline responsible for an issue.
Step 5: Configure automated impact analysis workflows
Impact analysis workflows help teams understand the consequences of pipeline changes before they affect business users. Instead of manually tracing dependencies, lineage systems automatically identify affected assets.
Automated impact analysis should detect dependencies across:
-
Downstream datasets: Identify tables or datasets that rely on upstream pipeline outputs.
-
Analytics dashboards and reports: Highlight BI dashboards that could show incorrect metrics.
-
Business metrics and KPIs: Reveal which metrics depend on affected transformations.
-
Data consumers and stakeholders: Notify data owners and analysts who rely on impacted datasets.
These workflows allow teams to respond to pipeline issues faster and prevent incorrect analytics from spreading.
Step 6: Operationalize governance and continuous monitoring
The final step is embedding lineage into governance and operational monitoring practices. Lineage should remain continuously updated as pipelines evolve and new systems are added.
Operational lineage dashboards should provide visibility into:
-
Live dependency graphs: Show how data moves across pipelines, datasets, and reporting layers.
-
Recent pipeline changes: Highlight schema updates, transformation changes, and pipeline deployments.
-
Data quality alerts: Connect monitoring signals directly to lineage graphs for faster root-cause analysis.
-
Historical lineage replay: Allow teams to review past pipeline states during investigations.
|
Practical resource for implementing data governance
|
How to evaluate real-time lineage monitoring solutions
Not all lineage tools are designed to support modern streaming environments. When evaluating real-time lineage monitoring solutions, organizations should assess whether the platform can handle continuous data flows, dynamic dependencies, and large-scale distributed architectures.
The checklist below highlights the key capabilities teams should evaluate when comparing lineage platforms.
|
Evaluation Criteria |
What to look for |
|
Streaming data lineage support |
Tracks data movement across streaming platforms such as Kafka, CDC pipelines, and event-driven systems without relying on batch metadata scans. |
|
Column-level dynamic lineage tracking |
Provides field-level visibility to trace how individual attributes move through transformations and impact downstream datasets. |
|
Integration with observability tools |
Connects lineage with monitoring and data quality systems to detect pipeline issues and trace root causes faster. |
|
Continuous monitoring dashboards |
Displays live dependency graphs, pipeline health indicators, and recent pipeline changes in one centralized view. |
|
Historical lineage replay |
Allows teams to review past pipeline states during incident investigations or compliance audits. |
|
Scalability across distributed architectures |
Ensures the lineage platform can support complex environments with multiple pipelines, cloud systems, and analytics platforms. |
|
Support for open standards |
Enables interoperability with different tools and reduces the risk of isolated metadata silos. |
Evaluating these capabilities helps organizations select lineage platforms that support both operational monitoring and long-term governance in modern data ecosystems.
Conclusion
Modern streaming architectures require more than static lineage diagrams and delayed documentation.
Real-time data lineage tracking gives teams continuous visibility into how data moves across pipelines, helping them detect issues early and understand the impact of upstream changes before they affect dashboards, reports, or applications.
The next step for organizations is to move from static documentation to operational lineage monitoring. Start by mapping pipelines, enabling streaming metadata capture, and connecting lineage with data quality and observability workflows. This approach helps teams trace dependencies faster and maintain trust in analytics.
Platforms like OvalEdge support these capabilities by combining automated lineage tracking, metadata management, and governance in one platform.
Book a demo with OvalEdge to see how real-time lineage, impact analysis, and governance tools can help your teams monitor pipelines and maintain reliable data across your ecosystem.
FAQs
1. What is streaming data lineage?
Streaming data lineage tracks data movement and transformations continuously within event-driven and streaming pipelines. It captures metadata in real time, updating dependency graphs instantly to reflect changes across brokers, processing engines, warehouses, and downstream dashboards.
2. How does real-time lineage monitoring improve pipeline reliability?
Real-time lineage monitoring improves pipeline reliability by detecting schema changes, broken transformations, and dependency conflicts as they occur. It accelerates root-cause analysis, reduces downtime, and enables proactive alerts before downstream dashboards or reports are impacted.
3. Can real-time data lineage support regulatory compliance?
Yes. Real-time data lineage supports regulatory compliance by providing traceable, column-level visibility into how data moves and transforms across systems. It strengthens audit readiness, supports reproducible impact analysis, and enables transparent documentation for financial, healthcare, and privacy regulations.
4. Does live data lineage impact system performance?
Modern live data lineage systems use lightweight metadata capture and event-driven updates, minimizing performance overhead. When architected properly, they operate independently from core processing pipelines, ensuring continuous monitoring without degrading streaming throughput or query performance.
5. How is dynamic lineage tracking different from metadata management?
Dynamic lineage tracking focuses on continuously updating data dependency relationships across pipelines. Metadata management organizes and catalogs technical and business metadata. Real-time lineage adds operational visibility by linking metadata changes directly to live pipeline monitoring and impact analysis.
6. What industries benefit most from real-time lineage tracking?
Industries with high-volume streaming environments benefit most, including financial services, retail, telecommunications, healthcare, and SaaS platforms. These sectors rely on continuous analytics, regulatory traceability, and rapid incident resolution to maintain operational reliability and compliance.
Deep-dive whitepapers on modern data governance and agentic analytics

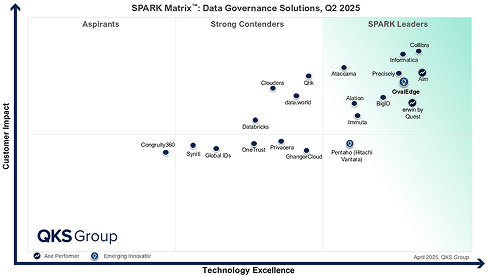
OvalEdge Recognized as a Leader in Data Governance Solutions
3ff1.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
aef2.png)
“Reference customers have repeatedly mentioned the great customer service they receive along with the support for their custom requirements, facilitating time to value. OvalEdge fits well with organizations prioritizing business user empowerment within their data governance strategy.”
Gartner, Magic Quadrant for Data and Analytics Governance Platforms, January 2025
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER and MAGIC QUADRANT are registered trademarks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.